خبر, کلودفلر, هوش مصنوعی
جداسازی خزنده های گوگل تنها راه برای اینترنتی عادلانه (پیشنهادات کلودفلر و تحلیل استاد آیتی)
تیم تحریریه استاد آی تی گزارش می دهد: در دنیای امروز که هوش مصنوعی به سرعت در حال دگرگون کردن صنایع مختلف است، نحوه جمع آوری و استفاده از داده ها توسط شرکت های بزرگ فناوری، به یکی از چالش های اصلی تبدیل شده است.
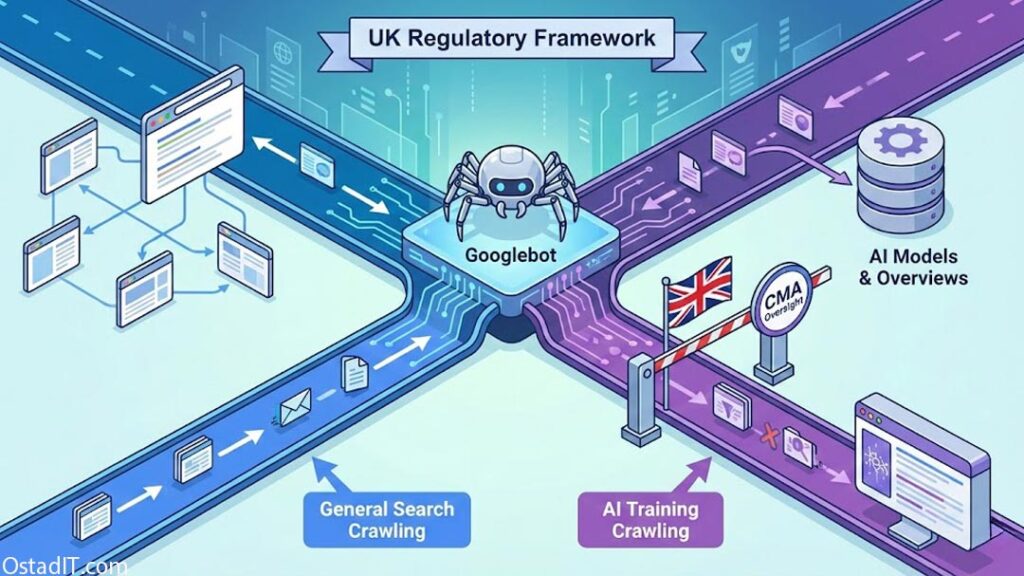
اخیرا، سازمان رقابت و بازارهای بریتانیا (CMA) مشاوره ای را در مورد الزامات رفتاری پیشنهادی برای گوگل آغاز کرده است. این اقدام با هدف رسیدگی به عدم انتخاب و شفافیت ناشران در مورد نحوه استفاده گوگل از جستجو برای تقویت خدمات و ویژگی های هوش مصنوعی مولد خود صورت گرفته است. این تحولات، بحث های گسترده ای را در مورد لزوم «جداسازی خزنده های گوگل» و تاثیر آن بر اکوسیستم دیجیتال به راه انداخته است.
چالش های فعلی و نگرانی های ناشران
گوگل با داشتن سهم ۹۰ درصدی از بازار جستجو در بریتانیا، توسط CMA به عنوان دارای «وضعیت بازار استراتژیک» (Strategic Market Status – SMS) در زمینه جستجوی عمومی و تبلیغات جستجوگر شناخته شده است. این عنوان، شامل قابلیت های هوش مصنوعی مانند «AI Overviews» و «AI Mode» نیز می شود.
نگرانی اصلی اینجاست که گوگل از یک خزنده واحد به نام «Googlebot» برای اهداف مختلفی از جمله ایندکس کردن محتوا برای جستجوی سنتی و همچنین آموزش مدل های هوش مصنوعی خود استفاده می کند. این رویکرد، ناشران را در موقعیتی دشوار قرار می دهد؛ زیرا آنها برای دیده شدن در نتایج جستجو به Googlebot نیاز دارند، اما در عین حال نمی خواهند محتوایشان بدون کنترل و جبران مناسب، برای آموزش هوش مصنوعی گوگل مورد استفاده قرار گیرد.
ناکارآمدی راهکارهای فعلی گوگل
CMA پیشنهاد کرده است که گوگل باید کنترل «معنادار و موثر» بر نحوه استفاده از محتوای ناشران برای ویژگی های هوش مصنوعی را فراهم کند. همچنین، گوگل باید شفافیت بیشتری در مورد نحوه استفاده از محتوای خزیده شده برای هوش مصنوعی مولد و پوشش کنترل های مختلف ناشران ارائه دهد.
معرفی معماری Vertical Microfrontends و راهکار جدید Cloudflare (توسعه فرانت اند)
با این حال، کلودفلر، یکی از بازیگران اصلی در زیرساخت اینترنت، معتقد است که این راهکارها کافی نیستند. ابزارهای فعلی گوگل مانند «Google-Extended» و «nosnippet» که برای انصراف از استفاده محتوا در هوش مصنوعی طراحی شده اند، به گفته کلودفلر، نتوانسته اند به طور موثر از استفاده محتوا به روش هایی که ناشران نمی توانند کنترل کنند، جلوگیری کنند. این وضعیت، ناشران را در یک «وابستگی دائمی» به قوانین و پلتفرم گوگل قرار می دهد و انتخاب های آنها را محدود می کند.
جداسازی خزنده های گوگل: راهکاری برای اینترنتی عادلانه تر
کلودفلر پیشنهاد می کند که تنها راه حل موثر برای این مشکل، «جداسازی خزنده های گوگل» است. این به معنای تفکیک Googlebot به خزنده های مجزا برای اهداف مختلف است؛ به عنوان مثال، یک خزنده برای ایندکس کردن جستجوی سنتی و یک خزنده دیگر برای آموزش هوش مصنوعی.
این جداسازی به ناشران این امکان را می دهد که به طور مستقل تصمیم بگیرند که آیا می خواهند محتوایشان برای آموزش هوش مصنوعی استفاده شود یا خیر، بدون اینکه حضورشان در نتایج جستجوی سنتی به خطر بیفتد. این رویکرد، کنترل دانه بندی شده ای را در اختیار صاحبان وب سایت ها قرار می دهد که در حال حاضر فاقد آن هستند.
مزایای جداسازی خزنده ها
کارشناسان استاد آیتی معتقدند که جداسازی خزنده های گوگل نه تنها از نظر فنی امکان پذیر است، بلکه یک راهکار ضروری و متناسب برای ایجاد یک اکوسیستم دیجیتال عادلانه تر است. گوگل در حال حاضر نزدیک به ۲۰ خزنده تخصصی دیگر برای اهداف مختلف دارد، بنابراین تفکیک Googlebot بر اساس هدف، نباید یک چالش فنی غیرقابل حل باشد. این اقدام می تواند مزایای متعددی داشته باشد:
- کنترل بیشتر برای ناشران: ناشران می توانند به طور واضح مشخص کنند که کدام بخش از محتوایشان برای چه منظوری (جستجو یا هوش مصنوعی) قابل دسترسی است.
- رقابت عادلانه: با جداسازی خزنده ها، زمین بازی برای سایر شرکت های هوش مصنوعی هموارتر می شود و از سوء استفاده گوگل از انحصار جستجوی خود برای کسب مزیت ناعادلانه در بازار هوش مصنوعی جلوگیری می کند.
- تشویق نوآوری: این رویکرد، نوآوری را در بازار هوش مصنوعی مولد و عامل محور (Agentic AI) تشویق می کند، زیرا شرکت ها باید برای دسترسی به محتوا، شرایط عادلانه تری را ارائه دهند.
- شفافیت بیشتر: جداسازی خزنده ها به شفافیت کلی در مورد نحوه استفاده از داده ها کمک می کند و اعتماد بین ناشران و پلتفرم ها را افزایش می دهد.
واژه نامه تخصصی
برای درک بهتر این موضوع، در ادامه به برخی از واژه های تخصصی اشاره می کنیم که در این حوزه کاربرد فراوان دارند:
- وضعیت بازار استراتژیک (Strategic Market Status – SMS): عنوانی که توسط نهادهای نظارتی به شرکت هایی با سهم بازار غالب و قدرت قابل توجه در یک حوزه خاص اعطا می شود.
- جداسازی خزنده ها (Crawler Separation): تفکیک ربات های خزنده وب (مانند Googlebot) بر اساس هدف یا عملکرد خاص، به جای استفاده از یک خزنده واحد برای همه منظورها.
- هوش مصنوعی مولد (Generative AI – GenAI): نوعی هوش مصنوعی که قادر به تولید محتوای جدید (مانند متن، تصویر، کد) بر اساس داده های آموزشی است.
- هوش مصنوعی عامل محور (Agentic AI): سیستم های هوش مصنوعی که می توانند به طور مستقل تصمیم بگیرند و اقداماتی را برای دستیابی به اهداف خود انجام دهند.
- AI Overviews: خلاصه های تولید شده توسط هوش مصنوعی که گوگل در بالای نتایج جستجو نمایش می دهد.
- Googlebot: ربات خزنده وب اصلی گوگل که برای ایندکس کردن صفحات وب استفاده می شود.
- Robots.txt: فایلی که وب سایت ها برای راهنمایی خزنده های وب در مورد اینکه کدام بخش از سایت را می توانند یا نمی توانند خزش کنند، استفاده می کنند.
- مکانیسم های انصراف (Opt-out mechanisms): ابزارهایی که به کاربران یا ناشران اجازه می دهند از جمع آوری یا استفاده از داده هایشان برای اهداف خاصی انصراف دهند.
- ایندکس کردن جستجو (Search Indexing): فرآیند جمع آوری، تجزیه و تحلیل و ذخیره سازی اطلاعات از وب سایت ها توسط موتورهای جستجو برای نمایش در نتایج جستجو.
- آموزش و استنتاج هوش مصنوعی (AI Training & Inference): آموزش به فرآیند تغذیه داده ها به یک مدل هوش مصنوعی برای یادگیری الگوها اشاره دارد، در حالی که استنتاج به استفاده از مدل آموزش دیده برای پیش بینی یا تولید خروجی می پردازد.
- معیارهای کیفیت کلیک (Click Quality Metrics): معیارهایی که برای ارزیابی ارزش و ارتباط کلیک های کاربران بر روی نتایج جستجو یا تبلیغات استفاده می شوند.
- رژیم رقابت بازارهای دیجیتال (Digital Markets Competition Regime): چارچوب قانونی که توسط نهادهای نظارتی برای تنظیم بازارهای دیجیتال و جلوگیری از رفتارهای ضدرقابتی ایجاد شده است.
- سلطه هایپرسکیلر (Hyperscaler dominance): اشاره به تسلط شرکت های بزرگ فناوری (مانند گوگل، آمازون، مایکروسافت) در ارائه خدمات ابری و زیرساخت های دیجیتال.
- اصول ربات هوش مصنوعی مسئول (Responsible AI bot principles): مجموعه ای از دستورالعمل ها و اخلاقیات برای توسعه و استقرار ربات های هوش مصنوعی به شیوه ای مسئولانه و شفاف.
جمع بندی و چشم انداز آینده
موضوع جداسازی خزنده های گوگل، صرفا فراتر از یک بحث فنی است؛ این یک مسئله حیاتی برای حفظ عدالت، رقابت و نوآوری در فضای دیجیتال است. حمایت گروه های بزرگی مانند Daily Mail Group، The Guardian و News Media Association از این پیشنهاد، نشان دهنده اهمیت و فوریت آن است.
با توجه به اینکه هوش مصنوعی به طور فزاینده ای در حال شکل دادن به نحوه دسترسی ما به اطلاعات است، اطمینان از اینکه این فناوری به شیوه ای عادلانه و شفاف توسعه می یابد، از اهمیت بالایی برخوردار است. CMA بریتانیا با توجه به این چالش ها، فرصتی تاریخی برای تعیین استانداردهایی دارد که می تواند نه تنها برای بریتانیا، بلکه برای کل جهان دیجیتال الگو باشد.
این اقدام می تواند به تضمین این موضوع کمک کند که مزایای هوش مصنوعی به جای تمرکز در دست یک شرکت، به طور گسترده تری توزیع شود و ناشران و تولیدکنندگان محتوا، کنترل واقعی بر دارایی های دیجیتال خود داشته باشند.
منبع:
Google’s AI advantage: why crawler separation is the only path to a fair Internet