meta, خبر, هوش مصنوعی
جداسازی صدا در متا: تحلیل مدل SAM Audio و آینده تولید محتوا

تیم تحریریه استاد آی تی گزارش می دهد: در ادامه روند معرفی مدل های بنیادین هوش مصنوعی، شرکت متا (Meta) اخیرا از مدل SAM Audio متا رونمایی کرده است. این مدل که به عنوان اولین مدل یکپارچه چندوجهی برای جداسازی صدا معرفی شده، قرار است همان نقشی را در حوزه صدا ایفا کند که مدل Segment Anything Model (SAM) در حوزه بینایی کامپیوتر ایفا کرد. هدف اصلی این نوآوری، تبدیل فرآیند پیچیده جداسازی عناصر صوتی از یک ترکیب صوتی شلوغ به یک عملیات ساده و بصری است که از طریق دستورات طبیعی و چندوجهی انجام می شود. این رویکرد، نه تنها کارایی را افزایش می دهد، بلکه نحوه تعامل انسان با محتوای صوتی را نیز متحول می سازد.
SAM Audio با تکیه بر یک معماری پیشرفته، محدودیت های ابزارهای سنتی را که اغلب برای یک هدف خاص طراحی شده بودند، از میان برمی دارد. این مدل با پشتیبانی از ورودی های متنی، بصری و زمانی، کنترل دقیق و شهودی را برای کاربران فراهم می کند. برای مثال، در یک ویدیوی ضبط شده از یک کنسرت، کاربر می تواند با کلیک کردن روی ساز گیتار در تصویر، صدای آن را به صورت مجزا استخراج کند. این سطح از یکپارچگی بینایی و شنوایی، مرزهای جدیدی را در تولید و ویرایش محتوا تعریف می کند.
معماری و نوآوری های کلیدی در مدل SAM Audio متا
نوآوری در مدل SAM Audio متا صرفا به قابلیت های کاربری محدود نمی شود، بلکه در عمق معماری فنی آن ریشه دارد. این مدل بر پایه یک چارچوب مدل سازی مولد (Generative Modeling Framework) ساخته شده که از یک ترانسفورمر انتشار تطبیق جریان (Flow-matching Diffusion Transformer) بهره می برد. این ساختار، ترکیب صوتی و پرامپت های ورودی را به یک نمایش مشترک رمزگذاری کرده و سپس ترک های صوتی هدف و باقیمانده را تولید می کند.
نقش موتور PE-AV در یکپارچه سازی بصری و صوتی
قلب تپنده مدل SAM Audio متا، موتور Perception Encoder Audiovisual (PE-AV) است. این موتور که توسعه یافته مدل Perception Encoder متا است، قابلیت های پیشرفته بینایی کامپیوتر را به حوزه صدا گسترش می دهد. PE-AV با استخراج ویژگی های ویدیویی در سطح فریم و هم ترازی آن ها با نمایش های صوتی، اطلاعات چندوجهی را با برچسب زمانی دقیق ترکیب می کند. این هم ترازی زمانی برای تطبیق آنچه دیده می شود با آنچه شنیده می شود، حیاتی است. بدون این مکانیسم، مدل فاقد درک بصری دقیق مورد نیاز برای جداسازی صوتی انعطاف پذیر و ادراکی خواهد بود. این قابلیت به SAM Audio اجازه می دهد تا منابع صوتی که دارای ریشه بصری هستند، مانند سخنرانان یا سازها در تصویر، را با دقت بالا جداسازی کند.
قابلیت های چندوجهی و پرامپت های نوین
SAM Audio سه روش اصلی برای جداسازی صدا ارائه می دهد که می توانند به صورت مجزا یا ترکیبی استفاده شوند:
- پرامپت متنی (Text Prompting): کاربر می تواند با تایپ عباراتی مانند “صدای پارس سگ” یا “صدای آواز خواندن”، صدای مورد نظر را استخراج کند.
- پرامپت بصری (Visual Prompting): با کلیک کردن روی یک شیء یا فرد در ویدیو، صدای مرتبط با آن شیء یا فرد جداسازی می شود.
- پرامپت بازه زمانی (Span Prompting): این روش که یک نوآوری در صنعت محسوب می شود، به کاربران اجازه می دهد تا بازه های زمانی خاصی را که صدای هدف در آن رخ می دهد، مشخص کنند. این قابلیت برای محتوای طولانی مانند پادکست ها یا مصاحبه ها که نیاز به حذف نویز در یک بازه مشخص دارند، بسیار کاربردی است.
تحلیل تاثیر مدل SAM Audio متا بر صنعت تولید محتوا
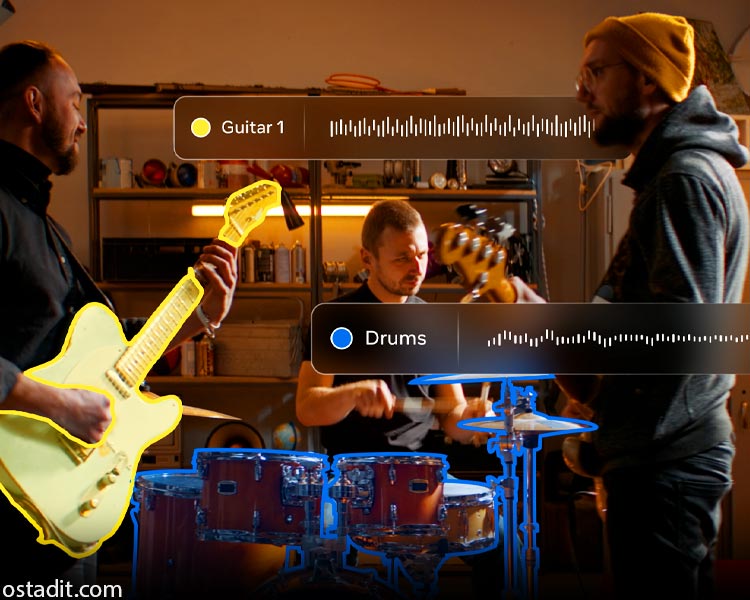
معرفی مدل SAM Audio متا یک تغییر پارادایم از ابزارهای تک منظوره به سمت یک پلتفرم یکپارچه را نشان می دهد. در گذشته، تولیدکنندگان محتوا مجبور بودند برای حذف نویز، جداسازی وکال یا تفکیک سازها از ابزارهای مختلف و اغلب پیچیده استفاده کنند. اکنون، یک مدل واحد با عملکردی سریع تر از زمان واقعی (RTF ≈ ۰.۷)، این وظایف را به صورت یکپارچه انجام می دهد. این سرعت و کارایی، به ویژه برای کسانی که در زمینه بازاریابی دیجیتال و تولید محتوای ویدیویی فعالیت می کنند، یک مزیت رقابتی بزرگ محسوب می شود.
کارشناسان استاد آی تی معتقدند که قابلیت های چندوجهی SAM Audio، به طور خاص پرامپت بصری، به طور چشمگیری زمان مورد نیاز برای پس تولید (Post-Production) محتوای ویدیویی را کاهش خواهد داد. این امر به کسب و کارها و آژانس های دیجیتال مارکتینگ اجازه می دهد تا با سرعت بیشتری محتوای باکیفیت تولید کنند. این مدل همچنین با ارائه SAM Audio Judge، یک معیار ارزیابی بدون نیاز به مرجع، کیفیت جداسازی را بر اساس درک انسانی می سنجد که این خود یک پیشرفت مهم در ارزیابی مدل های هوش مصنوعی صوتی است. برای کسب اطلاعات بیشتر در مورد آخرین تحولات فناوری، می توانید به بخش اخبار فناوری استاد آی تی مراجعه کنید.
محدودیت ها و چالش های پیش رو
با وجود پیشرفت های چشمگیر، مدل SAM Audio متا دارای محدودیت هایی نیز هست. این مدل در حال حاضر از صدا به عنوان پرامپت پشتیبانی نمی کند و جداسازی کامل صدا بدون هیچ پرامپتی خارج از دامنه عملکرد آن است. همچنین، جداسازی رویدادهای صوتی بسیار مشابه، مانند تفکیک صدای یک خواننده از یک گروه کر یا یک ساز از ارکستر، همچنان یک چالش باقی مانده است. با این حال، با توجه به مقیاس مدل (تا ۳ میلیارد پارامتر) و تعهد متا به انتشار آن به صورت متن باز، انتظار می رود که این مدل به سرعت توسط جامعه توسعه دهندگان بهبود یابد. (آموزش پرامپت نویسی)
جمع بندی
مدل SAM Audio متا نشان دهنده همگرایی هوش مصنوعی در حوزه های بینایی و شنوایی است و پتانسیل بالایی برای دموکراتیزه کردن ویرایش صوتی دارد. این مدل، ابزاری قدرتمند برای تولیدکنندگان محتوا، پادکسترها و توسعه دهندگان اپلیکیشن های خلاقانه خواهد بود.
منابع:
Introducing SAM Audio: The First Unified Multimodal Model for Audio Separation